





⚡Key Takeaways
- An enterprise data lake is a central repository that stores all your raw data, structured or unstructured, at scale
- Data lakes offer significant advantages over traditional data warehouses, including 50% lower storage costs and the ability to defer data transformation decisions until you actually need the insights
- To get the most value, follow best practices: strong data governance, clear metadata tags, and using embedded analytics tools like Qrvey to turn raw information into customer-facing insights
Your company generates terabytes of data every month but somehow you’re still making decisions based on gut feelings. This disconnect happens because traditional systems force you to decide how to structure your data before you even know what questions you’ll need it to answer.
An enterprise data lake changes this equation entirely. It lets you store all your raw data first and figure out the structure later when you’re ready to extract insights.
We’ll walk you through everything you need to build, implement, and maintain an enterprise data lake that delive`rs value instead of becoming another expensive storage graveyard.
What Is Enterprise Data Lake?
An enterprise data lake is a massive, centralized storage system that holds structured, semi-structured, and unstructured data in its raw data form. Unlike a Data Warehouse, which requires transformation before loading, a data lake uses a schema-on-read intelligence approach. This means you can store everything first and decide how to use it later.
This approach reflects what Bill Inmon, the “Father of the Data Warehouse,” calls the evolution of data architecture:
“Data architecture is like an ever evolving river…the evolution of data architecture now includes the data lake house, which includes a whole different type of data.”
Instead of spending months deciding how to structure your customer interaction data, social media feeds, or IoT sensor readings upfront, you can start collecting everything immediately and make those structural decisions when you have specific business questions to answer.
What are the Essential Elements of an Enterprise Data Lake
Every successful enterprise data lake needs these core components to function properly:
Data Ingestion and Movement
Your data lake needs robust pipelines that can handle everything from structured database exports to real-time streaming data from IoT devices. Modern ingestion systems automatically capture data from sources like social media APIs, customer interaction platforms, and legacy databases without requiring you to transform anything upfront.
Analytics and Processing Layer
Built-in processing capabilities let your data scientists run machine learning experiments directly on stored data without moving it elsewhere. This includes support for big data processing frameworks and the ability to handle both batch and real-time analytics workloads.
Security and Governance Framework
Enterprise-grade security controls ensure your data lake doesn’t become a compliance nightmare.
This includes metadata management systems, access controls, and audit trails that track who accessed what data when. Without proper governance, even the best-designed data lake can quickly become what experts call a “data swamp.”
Storage and Compute Separation
Modern data lakes separate storage from compute resources, letting you scale each independently based on your actual needs. This architectural decision directly impacts your costs since you only pay for the compute power you use while keeping storage costs minimal.
Organizations tackling the dark data problem find this separation particularly valuable for managing massive volumes of potentially useful information.
Enterprise Data Lake Architecture
The most successful enterprise data lake implementations follow a pattern called the medallion architecture pattern that processes data in stages, each serving specific business needs:
Raw Data Zone (Bronze Layer)
This is where all your unprocessed data lands first. Customer purchases, browsing behavior, server logs, and IoT sensor readings all flow into object storage systems like Amazon S3 or Azure Data Lake Storage.
The key principle here is capturing everything without losing any information; you can always decide later what’s valuable.
Processed Data Zone (Silver Layer)
Your raw data gets cleaned, standardized, and enriched in this layer. ETL processes remove duplicates, fix formatting issues, and add context that makes the data more useful for analysis. This is where you start applying business rules and data quality checks.
Curated Data Zone (Gold Layer)
Business-ready data lives here, organized and structured for specific use cases. Your analytics platform and dashboard tools primarily work with gold layer data because it’s optimized for query performance and business intelligence reporting.
Archive and Backup Zone
Historical data and regulatory compliance information sits in low-cost storage with appropriate retention policies. This zone ensures you meet legal requirements while keeping older data accessible for long-term trend analysis.
Pro Tip: Qrvey’s cloud-native architecture simplifies this entire setup by providing a built-in data lake powered by Elasticsearch that’s specifically designed for multi-tenant SaaS applications.
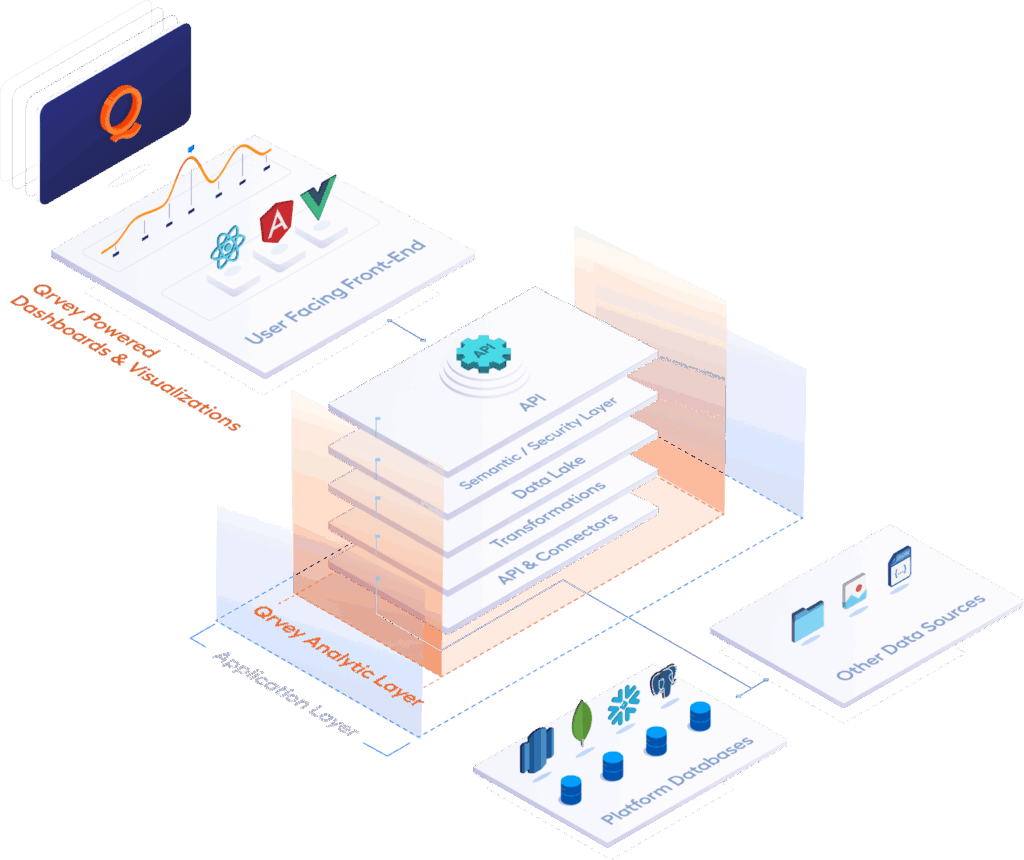
Instead of building and maintaining these zones yourself, you get enterprise-grade data management that scales with your customer base. This means you eliminate months of architecture planning with Qrvey’s embedded analytics.
“They (Qrvey) seem to understand the rigid nature of legacy BI solutions and put their efforts into being both responsive to their clients and being modern in their approach.” – verified G2 review
Benefits of an Enterprise Data Lake
When deciding whether an enterprise data lake is worth the investment, the first question every SaaS team asks is: what’s the payoff?
Cost Efficiency That Scales
Traditional data warehouses force you to pay premium prices for storage because everything must be structured upfront. Data lakes flip this model by using cheap object storage for the bulk of your data while only paying for compute resources when you actually process information.
This architectural difference can reduce your storage costs by 50% or more.
Flexibility for Unknown Future Needs
The Rethink Data survey reveals that only 32% of available enterprise data gets used, meaning 68% sits unused in traditional systems.
Data lakes solve this problem by storing everything cost-effectively until you discover new ways to extract value. You might not know today that your customer service chat logs contain insights about product defects but with a data lake, that data is ready when you make that connection.
Breaking Down Data Silos
Only 22% of business leaders say their teams share data well. Data lakes centralize information from disparate applications and legacy databases, making it accessible to authorized users across your organization.
Enterprise Data Lake vs Data Warehouse
Understanding when to use each system can save you thousands in cloud computing costs and months of DevOps specialists time.
Schema Approach Differences
Data warehouses use schema-on-write, forcing you to decide upfront how data should be structured. This works well when you have clearly defined reporting requirements that won’t change much over time. Data lakes use schema-on-read, letting you store data in its raw format and apply structure only when you need it for specific analyses.
Cost Structure Impact
While data warehouses excel at query performance for structured data, they become expensive when you need to store large volumes of diverse data types. The economic advantage of data lakes becomes more pronounced as your data volume grows.
Use Case Optimization
Data warehouses shine for daily operational reporting and business intelligence where you need consistent, fast query performance. Data lakes excel when you need flexibility for machine learning, predictive analytics, or handling unstructured data from sources like social media or IoT sensors.
Pro tip: Use data warehouses for mission-critical reporting that requires guaranteed performance. Choose data lakes when you need flexibility, cost efficiency, or plan to incorporate advanced analytics and machine learning into your strategy.
Common Challenges of Enterprise Data Lakes
What starts as a promising solution for data storage and analytics can quickly turn into an expensive problem if you don’t address these fundamental challenges from the beginning.
Data Quality and Governance Issues
IBM warns that “data lakes can struggle with data governance and data quality” without proper management systems. The schema-on-read approach that makes data lakes flexible also means you can easily lose track of what data you have, where it came from, and whether it’s accurate enough for business decisions.
The Data Swamp Problem
Without proper organization and metadata management, your data lake becomes what has been described as a collection of assets that “aren’t trusted or used.”
This happens when teams dump data without documenting its source, quality, or business context, making it nearly impossible for future users to determine if the data is suitable for their needs.
Performance and Query Optimization
Raw data stored in its native format isn’t optimized for query performance. Without proper organization, partitioning strategies, and processing pipelines, even simple analytics queries can become slow and costly.
These challenges multiply in multi-tenant SaaS environments, where strict data isolation must be balanced with self-service analytics for different customer segments.
Luckily, solutions like Qrvey’s enterprise-grade data lake, powered by Elasticsearch, tackle this by optimizing query performance at scale, delivering faster insights while keeping infrastructure costs under control.
Best Practices for Enterprise Data Lake Implementation
Building a successful data lake requires more than just dumping data into cloud storage. Here’s how to do it right:
Establish Strong Governance from Day One
When governance is an afterthought, you end up with data swamps that consume resources without delivering insights.
For SaaS companies, this challenge multiplies across customer tenants. Qrvey addresses this complexity by deploying directly within your cloud environment, inheriting your existing security policies while maintaining strict tenant isolation.
This approach eliminates many compliance headaches that plague traditional embedded analytics solutions..
Implement Progressive Data Processing
Organize your data using the medallion architecture pattern we discussed earlier. Start with raw data in your bronze layer, apply cleaning and standardization in your silver layer, and create business-ready datasets in your gold layer. This staged approach lets you balance processing costs with data quality requirements.
Optimize for Cloud Economics
Storage costs can spiral quickly if you don’t implement proper data lifecycle management. Use appropriate file formats, implement compression strategies, and establish retention policies that balance compliance requirements with cost optimization.
Speaking of cost optimization, managing cloud expenses becomes critical as your data lake grows.
Download our free comprehensive guide on reasons Snowflake costs rise to get practical solutions that many data lake implementations benefit from.
Enterprise Data Lake Use Cases
Understanding how successful organizations leverage their data lakes helps you identify opportunities within your own business and avoid common implementation mistakes.
Customer Analytics and Personalization
SaaS companies collect customer interaction data, usage patterns, and feedback across multiple touchpoints. An enterprise data lake makes it possible to store all this information cost-effectively while running machine learning models to predict churn, optimize onboarding flows, and personalize user experiences.
With platforms like Qrvey, every component (data storage, governance, and embedded analytics) works together, so you analyze historical patterns alongside real-time behavior.

This provides actionable insights that create competitive advantages in customer retention.
IoT and Operational Intelligence
Manufacturing companies generate massive volumes of sensor data from equipment, environmental monitors, and quality control systems. Traditional databases can’t handle this volume economically but data lakes make it feasible to store everything and run predictive maintenance algorithms that prevent costly downtime.
Business Intelligence Modernization
Organizations moving from legacy databases to cloud-native solutions use data lakes as the foundation for analytics modernization. This supports self-service analytics and reduces dependence on IT teams for reporting.
Platforms like Qrvey take this even further by embedding a multi-tenant data lake directly into SaaS applications, allowing teams to deliver modern analytics faster, at lower cost, and with stronger governance.
Product Development and Innovation
Technology companies use data lakes to store application logs, user behavior data, and performance metrics that inform product development decisions.
This comprehensive data collection enables A/B testing, feature usage analysis, and identification of improvement opportunities that might not be visible in traditional analytics systems.
Explore Qrvey’s Embedded Analytics Solutions
Enterprise data lakes solve the storage and flexibility challenges but they’re only as valuable as the analytics experiences you build on top of them. Many organizations hit a wall here, successfully collecting massive amounts of data but struggling to deliver the insights their customers or stakeholders need.
Qrvey bridges this gap with embedded analytics that includes a built-in data lake powered by Elasticsearch, specifically designed for SaaS applications that need to serve analytics to their customers
Your customers get self-service dashboard capabilities and personalized analytics experiences without you needing to hire specialized data engineers or spend months on custom development.
View our pricing to see how we make enterprise-grade embedded analytics accessible for growing SaaS companies.

David is the Chief Technology Officer at Qrvey, the leading provider of embedded analytics software for B2B SaaS companies. With extensive experience in software development and a passion for innovation, David plays a pivotal role in helping companies successfully transition from traditional reporting features to highly customizable analytics experiences that delight SaaS end-users.
Drawing from his deep technical expertise and industry insights, David leads Qrvey’s engineering team in developing cutting-edge analytics solutions that empower product teams to seamlessly integrate robust data visualizations and interactive dashboards into their applications. His commitment to staying ahead of the curve ensures that Qrvey’s platform continuously evolves to meet the ever-changing needs of the SaaS industry.
David shares his wealth of knowledge and best practices on topics related to embedded analytics, data visualization, and the technical considerations involved in building data-driven SaaS products.
Popular Posts

Why is Multi-Tenant Analytics So Hard?
BLOG
Creating performant, secure, and scalable multi-tenant analytics requires overcoming steep engineering challenges that stretch the limits of...

How We Define Embedded Analytics
BLOG
Embedded analytics comes in many forms, but at Qrvey we focus exclusively on embedded analytics for SaaS applications. Discover the differences here...

White Labeling Your Analytics for Success
BLOG
When using third party analytics software you want it to blend in seamlessly to your application. Learn more on how and why this is important for user experience.