





⚡Key Takeaways
- Data lake analytics handles structured and unstructured data, enabling faster decisions, lower costs, and advanced features like predictive insights and AI
- Common use cases include self-service dashboards, custom reporting, governance, and real-time analytics
- Platforms like Qrvey simplify implementation by embedding analytics directly into your SaaS product for your clients
Cloud bills creeping up while analytics still lag behind? That’s the reality for many SaaS teams managing multi-tenant environments. Data lake analytics flips the script, delivering enterprise-scale query performance at a fraction of the cost.
Instead of patching together warehouses and ETL pipelines, data lakes simplify how you collect, manage, and analyze information.
In this guide, you’ll learn what data lake analytics is, the key benefits and use cases, the components involved, and how to implement it. We’ll also explore best practices and how Qrvey helps SaaS teams like yours offload analytics, saving time while keeping customers happy.
What Is Data Lake Analytics?
Data lake analytics represents a fundamental shift in how organizations approach data analysis. Rather than forcing data into predefined structures before storage, this approach embraces the messiness of real-world information by accepting everything in its raw form first.
The beauty is its flexibility: customer contact records sit alongside performance evaluations, sentiment analysis results mix with traditional sales metrics, and machine learning models process it all without requiring separate data pipelines.
This creates opportunities that traditional data warehouse approaches simply cannot match.
What makes this particularly powerful for SaaS companies is the multi-tenant nature of modern data lake analytics solutions – with Qrvey.
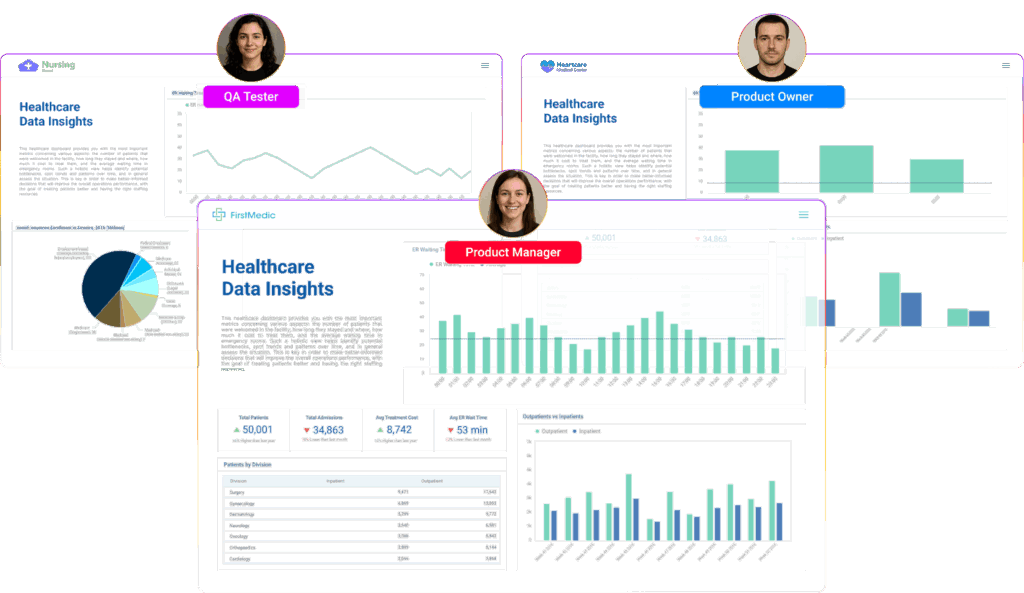
Each customer gets their own data space while sharing the same infrastructure, making advanced analytics affordable for all users, not just big enterprises.
Key Benefits & Use Cases of Data Lake Analytics
Data lakes are exploding in value, set to jump from $5.8 billion in 2022 to $34 billion by 2030. Still, the real story is how product teams rely on them to improve customer experiences.
Accelerated Product Development Cycles
Traditional analytics implementations create bottlenecks that slow down your entire product development process.
When customers request new reporting capabilities, your team faces weeks of database design, ETL development, and testing before anything reaches production.
Data lake analytics flips this timeline by storing raw data immediately and applying structure only when needed. Your customers can start exploring their information right away, while your team focuses on building core product features rather than maintaining complex data pipelines.
This approach directly addresses what 451 Research found in their survey: 38% of organizations cite improved product development as the top benefit of implementing a data lake. The reason becomes clear when you consider how much faster you can respond to customer needs when data is readily available.
Take a project management SaaS for instance: users create data from tasks, time tracking, and collaboration. Regular analytics may only show basic stats but data lake analytics uncovers deeper patterns like which projects lead to upgrades.
A tool like Qrvey turns raw data into ready-to-use insights through no-code analytics, so business users don’t have to wait on developers for reports.
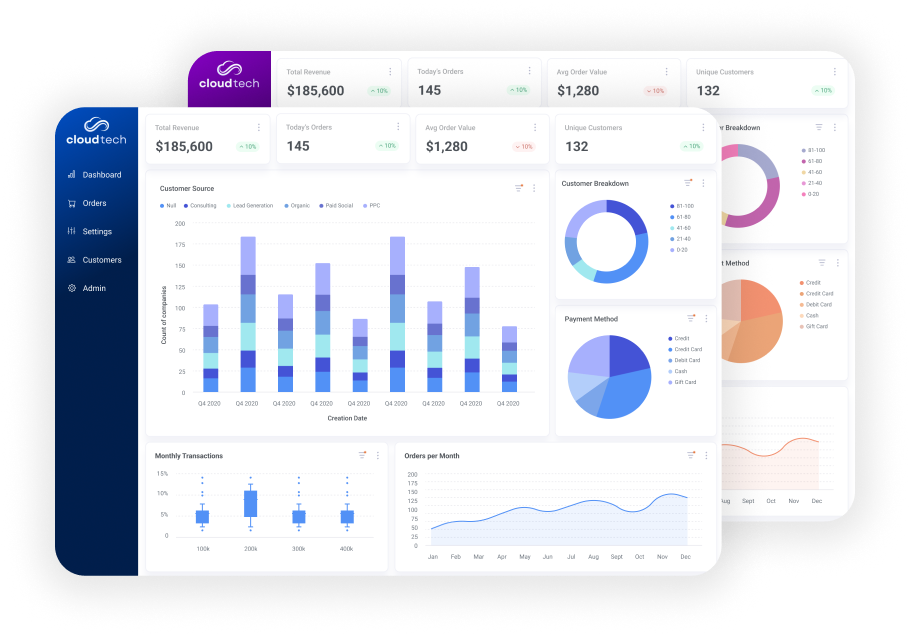
Enhanced Customer Retention Through Self-Service
Nothing frustrates SaaS users more than waiting for IT teams to generate reports they need for daily decision-making.
Philip Russom, a data management industry analyst, notes that “savvy users expect self-service access to lake data, and they will consider the lake a failure without it.”
When you embed data lake analytics capabilities directly into your application, customers gain immediate access to their information through intuitive dashboards and custom reports.
They can slice and dice data according to their specific needs without submitting tickets or waiting for development cycles.
This self-sufficiency transforms your analytics from a support burden into a competitive differentiator.
Cost Optimization at Scale
Traditional business intelligence tools charge per user, which creates an economic ceiling on how broadly you can deploy analytics capabilities. Enterprise customers might justify these costs, but smaller clients often get locked out of advanced features.
Data lake analytics built for multi-tenant environments break this constraint by sharing infrastructure costs across your entire customer base. Instead of paying licensing fees for each user, you pay for the underlying compute and storage resources that serve everyone.
Regulatory Compliance Made Simple
The same 451 Research survey revealed that 34% of organizations implement data lakes specifically for regulatory compliance benefits. This makes sense when you consider how compliance requirements constantly evolve and expand.
Data lake analytics provides an audit trail for every piece of information that flows through your system.
When compliance officers need to demonstrate data lineage or prove deletion requests were honored, everything exists in one searchable repository rather than scattered across multiple systems and databases.
The Core Components and Process of Data Lake Analytics
The data lake market is growing fast and success with data lake analytics comes from knowing how its parts work together to turn raw data into insights. It may sound complex, but modern tools make it simple with easy interfaces.
Data Ingestion and Storage Layer
The foundation starts with getting data into your data lake from multiple sources simultaneously. Log sources, OLTP databases, customer surveys, and third-party APIs all contribute streams of information that need processing and organization.
Azure Data Lake Storage Gen 2 and similar cloud services provide the scalable foundation that grows with your needs. But the real magic happens in how this data gets structured for multi-tenant access: each customer’s information remains isolated while sharing the underlying infrastructure.
Qrvey’s approach to this challenge involves creating tenant-specific data models that can be customized without affecting other users. This means Customer A can have different fields and calculations than Customer B, even though they’re using the same underlying platform architecture.
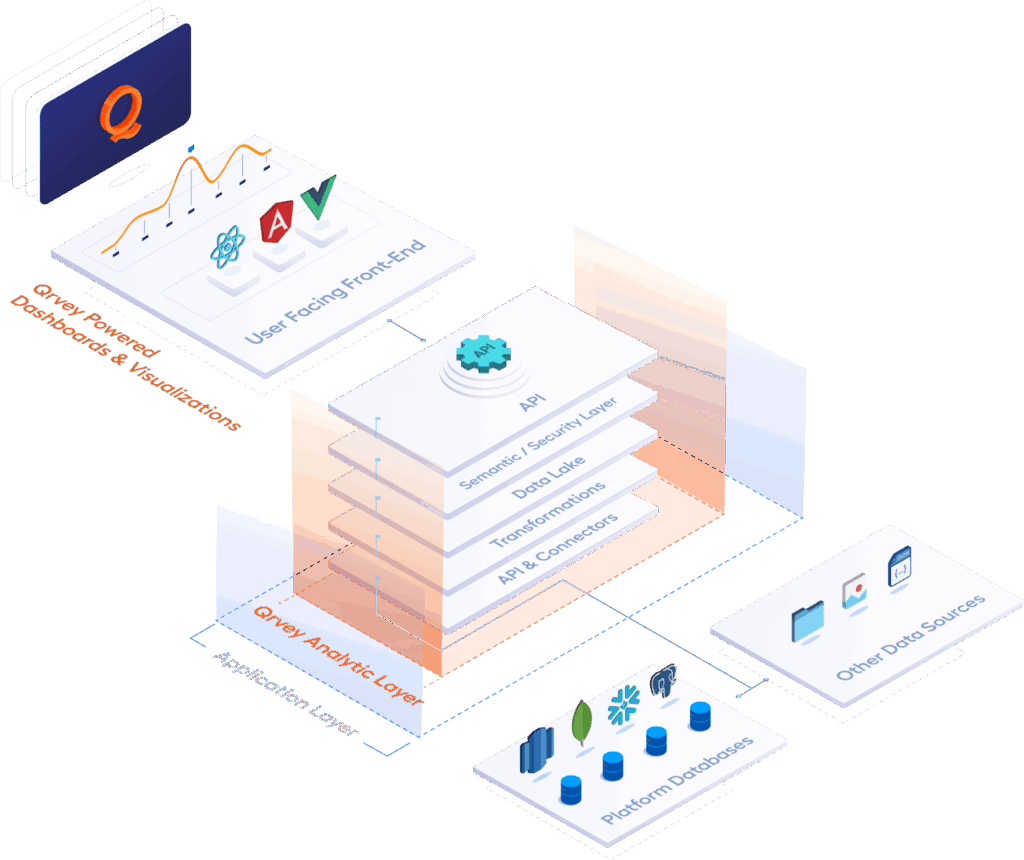
Processing and Analytics Engine
Raw data sitting in storage doesn’t generate insights until processing engines transform it into useful information. This is where technologies like Azure Synapse Analytics and distributed analytics services come into play, handling everything from simple aggregations to complex machine learning workflows.
The key insight that Philip Russom emphasizes is “adopting the practice of early ingestion and late processing” This approach means your customers can start seeing their data immediately, even if advanced analytics features come online gradually.
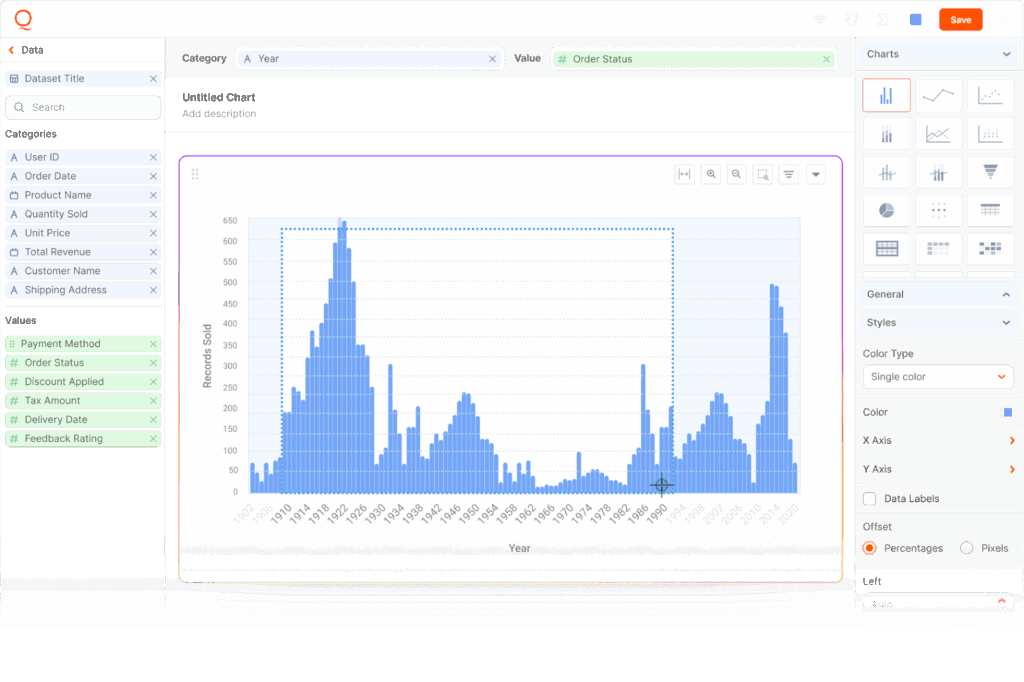
User Interface and Visualization Layer
The most sophisticated data lake becomes worthless if users can’t access insights through intuitive interfaces. This layer includes everything from drag-and-drop dashboard builders to SQL queries for power users who prefer direct database access.
What distinguishes embedded analytics platforms is how seamlessly they integrate with your existing application flow. Rather than redirecting users to separate Power BI reports or external dashboards, the analytics experience feels like a natural extension of your core product.
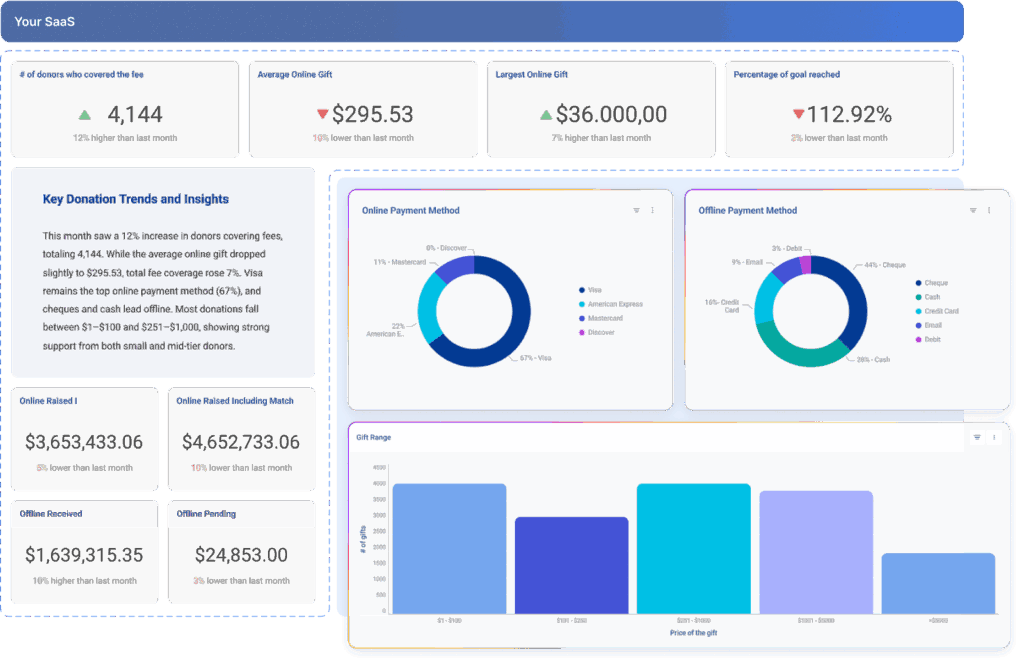
Users shouldn’t need separate credentials or permissions to access analytics features.
How to Implement a Data Lake Analytics Strategy
One of the hardest parts of data lake analytics is often the people. Many teams fail by underestimating the change from traditional reporting to self-service analytics.
Define Clear Business Objectives
What specific problems are you trying to solve with data lake analytics?
Your implementation strategy should align with these core objectives rather than trying to solve everything simultaneously. A product team focused on reducing feature request backlogs will approach data lake design differently than a compliance-driven organization managing regulatory reporting requirements.
Start by identifying the top three analytics pain points your customers currently experience. These might include slow report generation or inability to combine data from multiple sources.
Start with a Focused Pilot Project
Another big mistake organizations make is attempting to migrate all analytics workloads to a data lake simultaneously. This creates complex dependencies and increases the likelihood of project failure during critical migration periods.
Instead, choose one specific use case that demonstrates clear value while minimizing technical complexity.
Customer onboarding analytics, monthly recurring revenue tracking, or user engagement dashboards make excellent pilot projects because they involve familiar data sources and well-understood business logic.
Establish Data Governance Early
What happens when customer data gets mixed up between tenants, or when users accidentally access information they shouldn’t see?
These scenarios destroy customer trust and can trigger serious compliance violations that damage your business reputation.
Implementing proper data governance from day one prevents these issues from occurring. This includes establishing role-based access control, defining data retention policies, and creating audit trails that track every access and modification to sensitive information.
Download our practical guide on rising Snowflake costs to understand how governance decisions impact your long-term infrastructure costs & customer satisfaction metrics.
Challenges and Best Practices
Getting value from data lake analytics isn’t always easy. 29% of companies struggle to access and find their data, while 25% say organizing it is the hardest part. So, how can you overcome these hurdles and actually put your data to work?
Data Quality and Consistency Management
Raw data entering your data lake comes from systems with different validation rules, formatting standards, and update frequencies. Customer information from your CRM might conflict with usage data from your application logs, creating confusion when users try to generate unified reports.
Establishing data quality standards early prevents these inconsistencies from compounding over time. This includes:
- Implementing validation rules at ingestion points
- Standardizing date formats and naming conventions
- Creating automated processes that flag anomalies before they reach customer dashboards
Build quality checks that run automatically rather than relying on manual reviews.
When sentiment analysis results seem unusually positive or performance evaluations show impossible completion rates, your system should flag these issues for investigation rather than displaying potentially incorrect information to users.
Security and Access Control Complexity
Managing security in a multi-tenant data lake environment creates challenges that don’t exist in traditional single-tenant applications.
Each customer needs access to their own data while remaining completely isolated from other tenants, even when using shared computing resources and storage infrastructure.
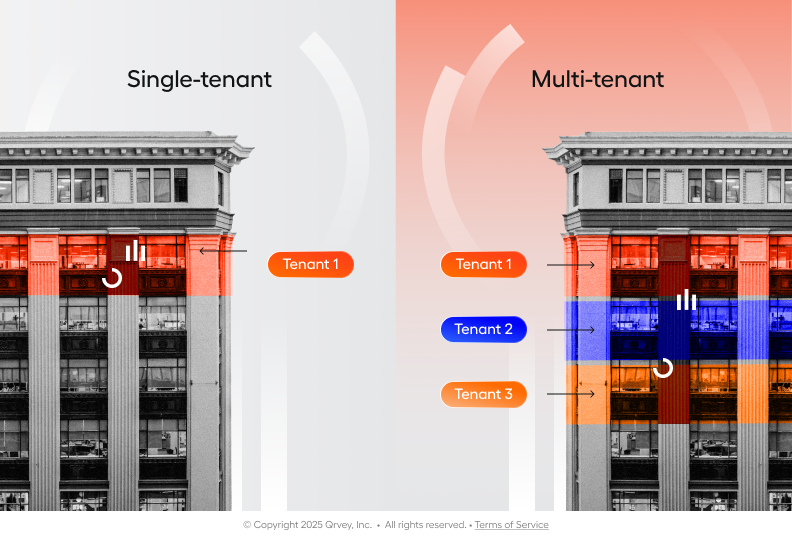
Tools like Microsoft Entra ID helps streamline authentication flows but the real complexity lies in managing permissions at the data level.
For example, Customer A’s marketing team should only see marketing data, while finance sees finance data, and neither should touch Customer B’s.
The safest approach is layering security at every level: network, database, app, and UI. That way, if one layer fails, the data stays protected.
Pro tip: Use token-based authentication to grant permissions on the fly, so you don’t need separate user accounts in your analytics system
Performance Optimization for Multi-Tenant Workloads
Shared data lakes often slow down when multiple users run complex queries as one inefficient query can drag down performance for everyone.
While cloud providers like Azure offer partial fixes, they don’t eliminate the problem.
Qrvey solves this by automatically optimizing queries, caching results, and partitioning tenant data for speed. Plus, built-in governance ensures no single user consumes all the resources. And you get reliable, consistent performance across all customers.
Start a free demo of Qrvey to see how effortless multi-tenant analytics can be.
Leverage Qrvey To Make the Most of Your Data Lake Analytics
Building data lake analytics from scratch takes skills most SaaS teams don’t have: data engineering, security, UI design, and ongoing upkeep.
Instead of hiring specialists and managing heavy infrastructure, Qrvey lets you embed powerful analytics directly into your app. With features like multi-tenant security, self-service dashboards, and smooth integration, you deliver what customers want without the cost or delay.
22% of companies plan to adopt data lakes in the next three years, so early movers have a chance to stand out.
Book a demo to see how Qrvey turns raw data into engaging customer experiences that reduce churn and fuel revenue.

David is the Chief Technology Officer at Qrvey, the leading provider of embedded analytics software for B2B SaaS companies. With extensive experience in software development and a passion for innovation, David plays a pivotal role in helping companies successfully transition from traditional reporting features to highly customizable analytics experiences that delight SaaS end-users.
Drawing from his deep technical expertise and industry insights, David leads Qrvey’s engineering team in developing cutting-edge analytics solutions that empower product teams to seamlessly integrate robust data visualizations and interactive dashboards into their applications. His commitment to staying ahead of the curve ensures that Qrvey’s platform continuously evolves to meet the ever-changing needs of the SaaS industry.
David shares his wealth of knowledge and best practices on topics related to embedded analytics, data visualization, and the technical considerations involved in building data-driven SaaS products.
Popular Posts

Why is Multi-Tenant Analytics So Hard?
BLOG
Creating performant, secure, and scalable multi-tenant analytics requires overcoming steep engineering challenges that stretch the limits of...

How We Define Embedded Analytics
BLOG
Embedded analytics comes in many forms, but at Qrvey we focus exclusively on embedded analytics for SaaS applications. Discover the differences here...

White Labeling Your Analytics for Success
BLOG
When using third party analytics software you want it to blend in seamlessly to your application. Learn more on how and why this is important for user experience.