





⚡ Key Takeaways
- Data lake helps you handle unstructured and structured data sources, improve data quality, and deliver real-time analytics across industries
- Big brands like Nestlé USA and other industry giants use cloud-native data lakes to cut costs by up to 50% and improve speed-to-insight
- Solutions like Qrvey allow SaaS teams to deliver embedded real-time dashboards for their clients without building analytics in-house
Your data lives everywhere. Customer interactions scatter across support tickets, purchase records, and social media mentions while your team wastes hours trying to piece together a complete picture.
This fragmentation costs opportunities. The enterprise data lake market reflects this urgency, growing from $7.05 billion in 2023 toward a projected $34.07 billion by 2030. So, organizations are betting on unified data strategies because scattered information leads to scattered results.
This guide breaks down the most impactful data lake use cases you need to know about. You’ll discover real business examples, see how industry giants leverage these architectures, and learn practical implementation strategies that deliver results.
What Is a Data Lake: A Quick Reminder
A data lake stores raw information from multiple sources without forcing it into rigid structures first. Unlike traditional databases that demand clean, organized data upfront, data lakes accept everything (messy customer emails, sensor readings, purchase records, and video files) then let you decide how to use it later.
This flexibility becomes important when business needs change faster than IT can restructure databases. You can explore database vs data warehouse vs data lake or learn how to build data lake environments to see which approach fits your specific requirements.
2026 Top Data Lake Use Cases
As cloud costs rise and data silos grow, the leading data lake use cases for 2026 focus on solving real pain points: scalability, speed, and simplified analytics.
AI Model Training and Machine Learning
Machine learning algorithms need massive amounts of historical data to identify patterns that humans miss. Data lakes excel here because they preserve original data formats that AI models can consume directly, rather than forcing everything through transformation processes that might remove important signals.
Consider a retail company training models to predict which customers will churn. Traditional databases might store only purchase amounts and dates, but data lakes can include the original customer service chat logs, email subject lines, and website browsing patterns that reveal early warning signs.
Real-Time Customer Analytics for SaaS Platforms
SaaS companies face unique challenges when providing analytics to customers. Each client needs personalized dashboards showing their own data, but building custom reporting for thousands of tenants creates massive engineering overhead.
Data lakes solve this by centralizing customer usage data, feature adoption metrics, and support interactions in one flexible repository.
Rather than building separate analytics infrastructure, companies can use platforms like Qrvey’s data lake analytics to deliver personalized insights without the development burden. Qrvey for embedded analytics makes it easy to turn that data into secure, customer-facing dashboards that feel native inside your SaaS product.
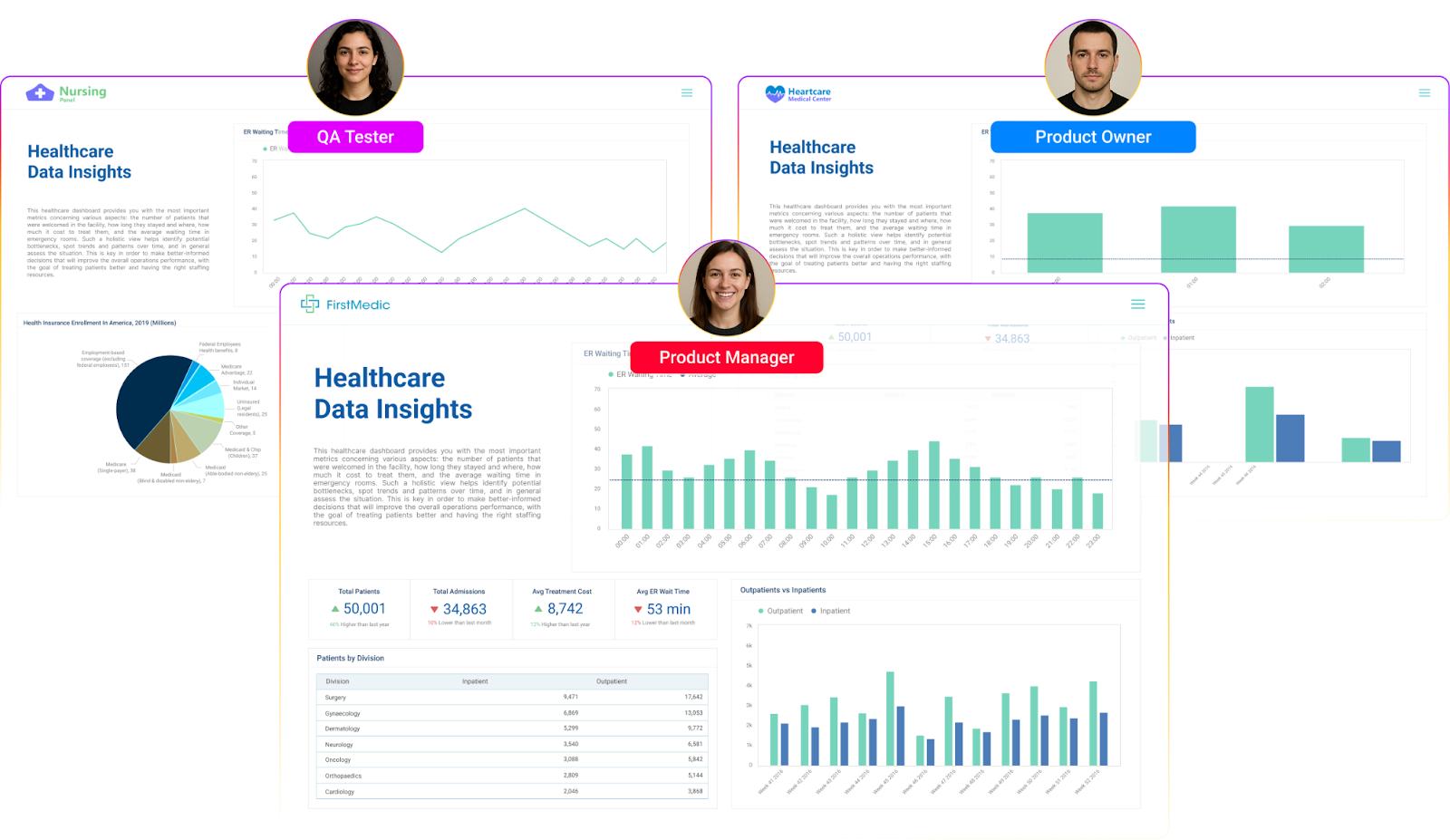
This approach transforms analytics from a cost center into a competitive advantage. Customers stay longer when they can easily track their own ROI and usage patterns.
Supply Chain Optimization
Manufacturing companies collect data from suppliers, transportation partners, production facilities, and retail locations. But traditional systems may struggle to connect these diverse sources, leaving supply chain managers making decisions based on incomplete information.
Data lakes centralize everything: supplier quality reports, shipping delays, weather data affecting transportation, and point-of-sale information from retailers. Companies using supply chain analytics software can then identify bottlenecks and optimize inventory levels across the entire network.
Healthcare Data Integration
Healthcare organizations struggle with data scattered across electronic health records, medical imaging systems, lab results, and insurance claims. Each system uses different formats, making comprehensive patient analysis nearly impossible.
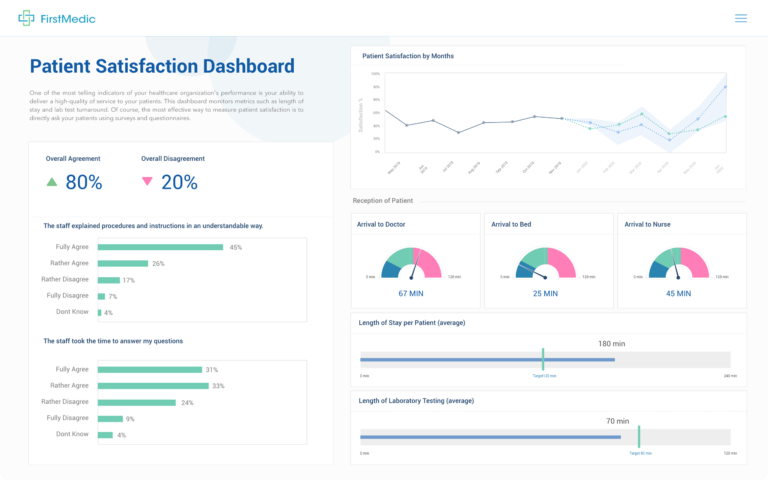
Data lakes allow healthcare providers to store all patient information in one location while maintaining the original formats required by different medical systems. This allows for population health studies, clinical trial matching, and personalized treatment recommendations that weren’t possible when data remained siloed.
Financial Risk and Compliance Analytics
Financial institutions must analyze vast amounts of transaction data, market information, and regulatory reports to identify risks and ensure compliance.
According to 451 Research, improving regulatory compliance is a top benefit for 34% of data lake implementations.
Banks use data lakes to combine structured transaction records with unstructured sources like news feeds and social media posts that might indicate market volatility or customer credit issues. This comprehensive view enables more accurate risk modeling and faster regulatory reporting.
IoT and Sensor Data Processing
Manufacturing equipment, smart buildings, and connected vehicles generate millions of sensor readings every hour. Traditional databases can’t handle this volume cost-effectively, while data lakes provide cheap storage that scales automatically.
Companies using IoT analytics platforms can store all sensor data in data lakes, then apply predictive analytics to identify equipment failures before they occur. This predictive maintenance approach reduces downtime while extending equipment life.
Content and Media Analysis
Media companies and marketing teams analyze customer-generated content like social media posts, product reviews, and video uploads. But traditional databases struggles with storing and analyzing multimedia effectively.
Data lakes excellently handle text, images, and video files equally well, for sentiment analysis, brand monitoring, and content recommendation engines that drive engagement and revenue.
Customer 360 and Personalization
Understanding customers requires combining data from multiple touchpoints: website visits, purchase history, support interactions, and social media engagement. Data lakes make this possible by storing all customer information in one place while preserving the original context.
This complete customer view enables personalized marketing campaigns, proactive customer service, and product recommendations that drive up to 25% revenue lift.
Avoid the most common mistakes when adding analytics capabilities to your software?Download our free guide that’s helped teams build better analytics experiences.
Real Business Examples of Data Lakes
The best way to understand the power of data lakes is by looking at how real companies are using them to cut costs, streamline analytics, and unlock new revenue opportunities.
Netflix’s Content Strategy
Netflix processes over 500 billion events daily through their data lake, combining viewing patterns with content metadata to power their recommendation engine.
Rather than just tracking what people watch, they analyze how long viewers hesitate before starting shows, when they pause or rewind, and which scenes cause people to stop watching.
This comprehensive approach drives a huge percentage of their viewing through recommendations, directly impacting their nearly $20 billion annual content budget by identifying which types of shows will succeed before expensive production begins.
Airbnb Personalization
Airbnb uses a data lake powered by Apache Iceberg to simplify how they manage massive amounts of event data. Instead of keeping separate hourly and daily datasets, they consolidate everything into one table. This makes data easier to query, improves consistency, and reduces costs by avoiding unnecessary duplication.
Their smart compaction process only rewrites files when needed, saving more than 50% in computing resources.
For users, this means fresher data, faster queries, and a single source of truth, all critical for powering Airbnb’s search, pricing, and personalization features.
Deloitte’s Improved Operations
Deloitte partnered with Nestlé USA to modernize its data strategy by building a Microsoft Azure Data Lake. This broke down silos and created reusable data assets across the company.
With AI and machine learning, Nestlé launched tools like the Sales Recommendation Engine, used weekly by 1,500+ sales reps, which boosted sales by 3%. Deloitte’s phased approach also helped retire 17 legacy systems, unify 15+ data sources, and drive over $200 million in business value.
“In the last four years, an estimated cumulative $200+ million worth of business value has been generated through projects and programs in the data lake.” – Deloitte
This is a great example of how data lakes directly impact growth and efficiency.
Data Lakes vs. Traditional Databases & Data Warehouses
While traditional databases and data warehouses were built for structured, transactional data, data lakes handle massive volumes of raw, diverse data, making them better suited for modern SaaS analytics.
Cost and Flexibility Trade-offs
Traditional data warehouses charge for both storage and processing power together, making it expensive to keep historical data that you might need later.
As Luv Aggarwal from IBM notes, “Data lakes offer lower cost solutions for big, unstructured data, but can often become data swamps and challenged with extracting insights in a highly performant and simplified way.”
The key is finding the right balance. Data lakes excel at storing diverse data types cheaply, while analytics platforms like embedded BI solutions provide the query performance that business users expect.
Performance vs. Accessibility
Data warehouses deliver fast query performance for structured data but they require significant technical expertise to set up and maintain. Data lakes store information more flexibly but raw queries can be slow without proper optimization.
The solution is layered architectures: data lakes providing the foundation while purpose-built analytics platforms, like Qrvey, handle user interactions. By sitting directly on top of a data lake, Qrvey enables self-service dashboards, reporting, and embedded analytics without forcing technical complexity onto business users.
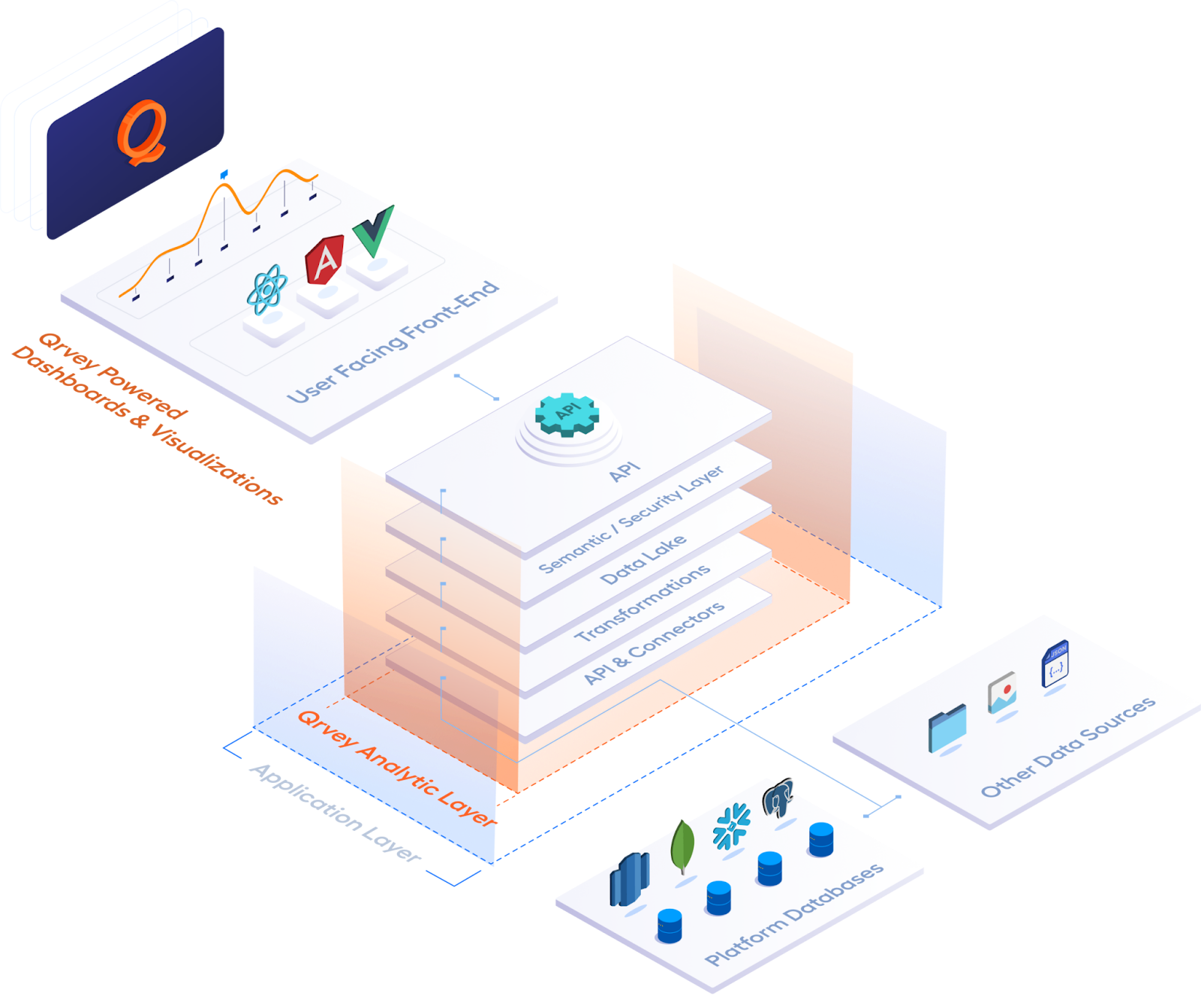
This approach gives SaaS teams both flexibility and performance, while reducing the development burden.
Challenges & Considerations of Data Lakes
While data lakes solve major problems around storage and scalability, they also introduce unique challenges that SaaS teams must address before going all in.
Data Quality and Governance
What happens when anyone can add data to your lake without standards? You end up with a data swamp where finding reliable information becomes impossible. The same 451 Research report shows that 82% of organizations expect data to become more important for decision-making, making governance key.
Successful data lake implementations establish clear data ownership, implement automated quality monitoring, and create catalogs that help users understand what data is available and how reliable it is.
Pro Tip: Invest in data cataloging tools early. They’re much harder to implement after your data lake grows large.
Performance and User Experience
Raw data queries can take minutes or even hours to complete, frustrating business users who expect dashboard updates in seconds. This performance gap often leads to abandoned data lake projects that once seemed promising.
Smart organizations address this by implementing analytics layers that pre-process common queries and provide intuitive interfaces.
Modern data analytics approaches like Qrvey’s embedded, self-service dashboards bridge the gap between data lake flexibility and user experience expectations. So, you give users the speed they want without forcing developers to build endless custom pipelines.
Security and Access Control
While traditional databases have well-established security models, data lakes often contain sensitive customer information, financial records, and proprietary business data scattered across millions of files.
Effective data lake security requires fine-grained access controls, encryption for data at rest and in transit, and comprehensive audit trails that track who accessed what information when.
Leverage Qrvey To Make the Most of Your Data Architecture
Your data lake investment only pays off when people can actually use the information it contains. So, the gap between data availability and business value often comes down to analytics capabilities: can your team easily explore the data, build dashboards, and share insights without waiting for IT support?
Qrvey’s embedded analytics platform transforms your data lake into actionable insights without the complexity of building everything in-house. Our multi-tenant architecture scales with your needs, whether you’re serving analytics to internal teams or thousands of customers.
Demo Qrvey for free today to see how embedded analytics can amplify your data lake investments.

Natan brings over 20 years of experience helping product teams deliver high-performing embedded analytics experiences to their customers. Prior to Qrvey, he led the Client Technical Services and Support organizations at Logi Analytics, where he guided companies through complex analytics integrations. Today, Natan partners closely with Qrvey customers to evolve their analytics roadmaps, identifying enhancements that unlock new value and drive revenue growth.
Popular Posts

Why is Multi-Tenant Analytics So Hard?
BLOG
Creating performant, secure, and scalable multi-tenant analytics requires overcoming steep engineering challenges that stretch the limits of...

How We Define Embedded Analytics
BLOG
Embedded analytics comes in many forms, but at Qrvey we focus exclusively on embedded analytics for SaaS applications. Discover the differences here...

White Labeling Your Analytics for Success
BLOG
When using third party analytics software you want it to blend in seamlessly to your application. Learn more on how and why this is important for user experience.