





⚡Key Takeaways
- Building a data lake is essential for organizations aiming to centralize, store, and analyze massive volumes of structured and unstructured data. It supports advanced analytics, AI, and machine learning initiatives, enabling data-driven decision-making at scale.
- A successful data lake implementation requires a clear understanding of business objectives, robust architecture, and a focus on governance, security, and scalability. Without these, data lakes can quickly become unmanageable “data swamps.”
- Data lakes differ fundamentally from data warehouses and cloud data lakes, offering greater flexibility, lower costs, and support for a wider variety of data types and analytics workloads. This makes them ideal for modern, agile organizations.
- Leveraging modern platforms like Qrvey can accelerate deployment, simplify data consumption, and ensure long-term value. These platforms provide embedded analytics, multi-tenant governance, and seamless integration with existing SaaS applications.
- Following best practices—such as automating data ingestion, cataloging, and enforcing security—ensures your data lake remains a valuable, accessible resource for all teams. Avoiding common pitfalls and understanding the unique challenges of data lakes will maximize your return on investment.
Organizations today are generating more data than ever before, but turning that raw information into actionable insights remains a major hurdle. Siloed systems, sluggish analytics, and rising storage costs can stifle innovation and slow down business growth. The answer lies in building a scalable data lake—a modern solution designed to centralize, organize, and unlock the true value of your data.
In this guide, you’ll discover exactly what a data lake is, why it’s critical for today’s enterprises, and how it stands apart from other data platforms. We’ll walk you through each step of the build process, share proven best practices, highlight common pitfalls, and provide real-world examples. Whether you’re a data engineer, product manager, or business leader, this resource will equip you to maximize your data’s potential and drive smarter, faster decisions from day one.

What is a Data Lake?
A data lake is a centralized repository designed to store, process, and analyze vast amounts of data in its native, raw format. Unlike traditional databases or data warehouses, which require data to be structured and cleaned before storage, data lakes can ingest data from a wide variety of sources—structured, semi-structured, and unstructured—without the need for upfront schema definition.
This means you can collect logs, sensor data, social media feeds, images, videos, and transactional records all in one place. The flexibility of schema-on-read allows organizations to define structure only when data is needed for analysis, making it easier to adapt to new data sources and business requirements.
Data lakes are typically built on scalable, low-cost storage solutions (such as Amazon S3 or Azure Data Lake Storage) and are designed to support advanced analytics, machine learning, and real-time processing. By democratizing access to data, data lakes empower teams across the organization to innovate, experiment, and make data-driven decisions faster than ever before.
Why Does a Data Lake Matter?
Data lakes have become a cornerstone of modern data architecture for several compelling reasons:
- Unmatched Scalability: Data lakes are built to handle petabytes or even exabytes of data, making them ideal for organizations experiencing rapid data growth. Whether you’re collecting IoT sensor data, customer interactions, or application logs, a data lake can scale seamlessly to accommodate your needs.
- Flexibility for All Data Types: Unlike data warehouses, which require data to be structured and cleaned before loading, data lakes can ingest raw data in any format—structured, semi-structured, or unstructured. This flexibility allows organizations to capture and store data from diverse sources without worrying about rigid schemas.
- Cost Efficiency: Leveraging cloud-based object storage, data lakes offer a cost-effective solution for storing massive volumes of data. Pay-as-you-go pricing models and tiered storage options help organizations optimize costs while maintaining accessibility.
- Advanced Analytics and AI: Data lakes enable data scientists and analysts to access raw, granular data for machine learning, predictive analytics, and real-time dashboards. This accelerates innovation and supports complex use cases that traditional data warehouses can’t handle.
- Data Democratization: By centralizing data in a single repository, data lakes break down silos and empower teams across the organization to access and analyze data securely. This fosters a culture of data-driven decision-making and collaboration.
- Future-Proofing Your Data Strategy: As business needs evolve, data lakes can easily adapt to new data sources, analytics tools, and regulatory requirements. This ensures your data infrastructure remains agile and responsive to change.
- Regulatory Compliance and Governance: Modern data lakes support robust governance frameworks, enabling organizations to enforce data quality, lineage, and access controls. This is critical for meeting regulatory requirements and maintaining trust with customers and stakeholders.
In summary, data lakes matter because they provide the foundation for scalable, flexible, and cost-effective data management—unlocking the full potential of your organization’s data assets.
Differences Between Data Lake vs Data Warehouse vs Cloud Data Lakes
| Feature | Data Lake | Data Warehouse | Cloud Data Lake |
| Data Types | Structured, semi/unstructured | Structured | Structured, semi/unstructured |
| Schema | Schema-on-read | Schema-on-write | Schema-on-read |
| Cost | Lower (cloud object storage) | Higher (compute + storage) | Pay-as-you-go |
| Use Cases | Big data, ML, IoT, analytics | BI, reporting, historical data | Big data, ML, analytics |
| Scalability | High | Moderate | Virtually unlimited |
| Performance | Variable (depends on query) | Optimized for SQL | Depends on cloud provider |
| Governance | Flexible, but needs strong setup | Mature, built-in | Cloud-native tools available |
1. Data Ingestion and Storage
Data lakes are designed to accept raw data in its native format, whether structured, semi-structured, or unstructured. This means you can ingest logs, images, videos, and transactional records without any transformation. In contrast, data warehouses require data to be cleaned, structured, and transformed before loading, which can slow down the onboarding of new data sources.
Cloud data lakes take this a step further by providing automated ingestion pipelines, serverless storage, and integration with a wide range of cloud-native services. This reduces the operational burden on IT teams and accelerates time-to-insight. For example, with AWS Glue or Azure Data Factory, organizations can automate the extraction, transformation, and loading (ETL) of data from multiple sources into the lake, ensuring data is always up-to-date and ready for analysis.
2. Schema and Flexibility
One of the most significant differences between data lakes and data warehouses is the approach to schema management. Data lakes use a schema-on-read model, allowing you to define the structure of your data only when you need to analyze it. This provides unparalleled flexibility, enabling organizations to store data without worrying about rigid schemas or frequent changes.
Data warehouses, on the other hand, use schema-on-write, which requires data to be structured and validated before it can be loaded. This can make it difficult to adapt to new data sources or evolving business requirements. Cloud data lakes inherit the flexibility of on-premises lakes but add features like automated schema inference, metadata management, and integration with data catalogs. This makes it easier for organizations to discover, organize, and analyze data at scale.
3. Analytics and Use Cases
Data lakes are optimized for advanced analytics, machine learning, and real-time processing. They provide access to raw, granular data, enabling data scientists and analysts to experiment, build models, and uncover insights that would be impossible with aggregated or pre-processed data. Data warehouses excel at business intelligence and reporting, offering fast, reliable SQL queries on structured data. However, they are less suited for unstructured data or complex analytics workloads.
Cloud data lakes combine the best of both worlds, offering scalable analytics engines, integration with machine learning platforms, and support for a wide range of analytics tools. For example, platforms like Qrvey enable organizations to embed analytics directly into their SaaS applications, delivering real-time insights to end users.
4. Cost and Scalability
Cost and scalability are critical considerations when choosing a data platform. Data lakes are typically more cost-effective for storing large volumes of diverse data, thanks to cloud object storage and pay-as-you-go pricing models. Data warehouses can become expensive as data volumes grow, especially when high-performance compute resources are required.
Cloud data lakes offer virtually unlimited scalability, allowing organizations to scale storage and compute independently based on their needs. This elasticity ensures you only pay for what you use, making it easier to manage costs and support dynamic workloads. Additionally, cloud providers offer tiered storage options, enabling organizations to optimize costs by moving infrequently accessed data to lower-cost storage classes.

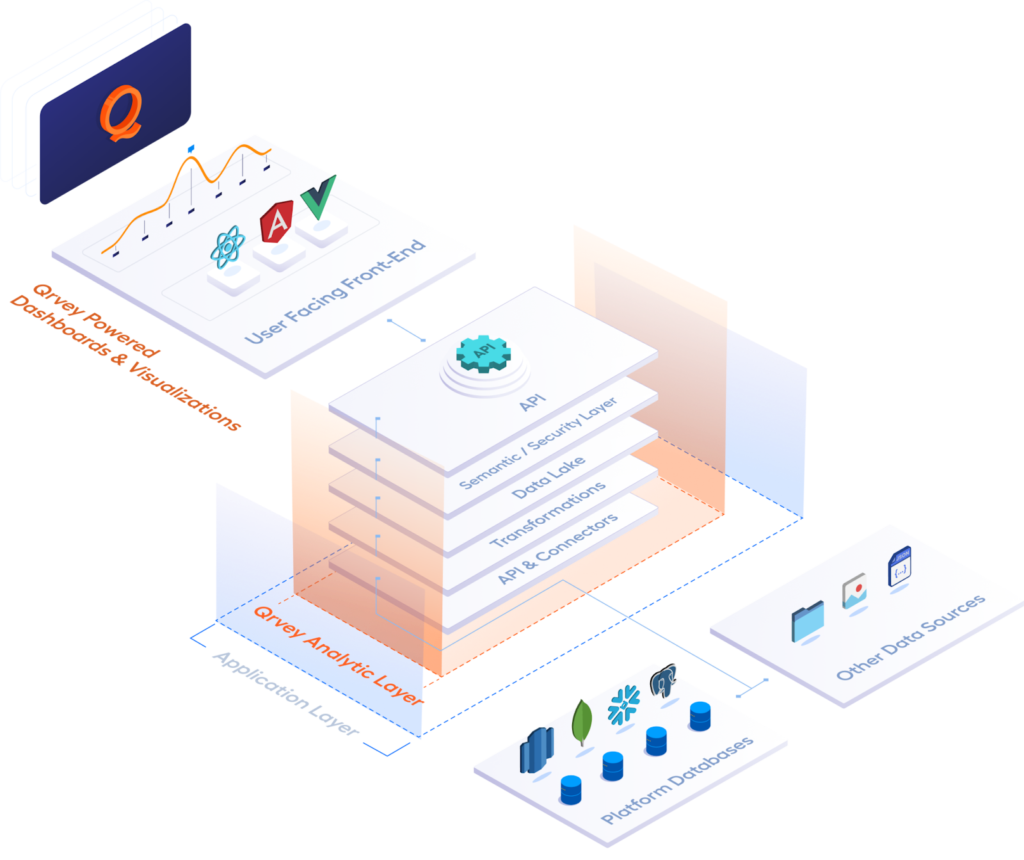
Core Components of a Data Lake Architecture
A robust data lake architecture is built on several key components, each playing a critical role in ensuring scalability, security, and usability:
- Data Ingestion Layer: This layer is responsible for collecting data from a wide variety of sources, including databases, IoT devices, logs, APIs, and third-party applications. Modern ingestion tools support batch and real-time streaming, enabling organizations to capture data as it is generated. Automated pipelines ensure data is consistently loaded into the lake, reducing manual effort and minimizing errors.
- Storage Layer: At the heart of every data lake is a scalable, durable storage solution. Cloud object storage services like Amazon S3, Azure Data Lake Storage, or Google Cloud Storage provide virtually unlimited capacity, high durability, and low cost. Data is typically stored in its raw format, with support for multiple file types (CSV, JSON, Parquet, images, etc.).
- Catalog and Metadata Management: As data volumes grow, it becomes essential to organize, index, and track data assets. Metadata management tools (such as AWS Glue Data Catalog or Apache Atlas) enable organizations to document datasets, track lineage, and enforce governance policies. This makes it easier for users to discover and understand available data.
- Processing and Analytics Layer: This layer enables data transformation, cleansing, and analytics using distributed processing engines like Apache Spark, Databricks, or Qrvey. Organizations can run batch jobs, real-time analytics, and machine learning workflows directly on data stored in the lake, unlocking new insights and use cases.
- Security and Governance: Protecting sensitive data is paramount. The security layer implements access controls, encryption (at rest and in transit), auditing, and compliance policies. Role-based access ensures only authorized users can access specific datasets, while monitoring and logging provide visibility into data usage and potential threats.
How to Build a Data Lake: Step-by-Step
Step 1: Define Business Objectives and Data Sources
The foundation of any successful data lake project is a clear understanding of business objectives. Begin by engaging stakeholders across the organization to identify the key goals your data lake should support—whether it’s improving customer insights, enabling predictive analytics, or supporting regulatory compliance.
Next, inventory all relevant data sources, including internal systems (CRM, ERP, transactional databases), third-party APIs, IoT devices, and external datasets. Prioritize use cases based on business value and feasibility, and document data ownership, quality requirements, and expected outcomes. This upfront planning ensures alignment between IT and business teams, reduces scope creep, and sets the stage for a data lake that delivers real, measurable value.
Step 2: Choose the Right Platform and Storage
Selecting the right platform is critical for scalability, performance, and cost management. Here’s how you should approach platform selection:
- Evaluate cloud providers (AWS, Azure, Google Cloud) and on-premises solutions based on your organization’s needs, existing infrastructure, and integration requirements.
- Consider factors such as storage durability, availability, security features, and support for multiple data formats.
- Opt for object storage solutions that offer high durability, low latency, and flexible pricing models.
- Assess the ecosystem of tools and services available for data ingestion, processing, and analytics.
- Ensure the platform supports seamless integration with your existing data architecture and can scale as your data volumes and analytics needs grow.
- Document your selection criteria and involve both technical and business stakeholders in the decision-making process.
Step 3: Design Data Ingestion and ETL Pipelines
Robust data ingestion and ETL (Extract, Transform, Load) pipelines are essential for ensuring data quality, consistency, and timeliness. Leverage modern tools like Apache NiFi, AWS Glue, Azure Data Factory, or open-source frameworks to automate the extraction of data from source systems, transformation into usable formats, and loading into the data lake.
Design pipelines to handle both batch and real-time streaming data, enabling near-instant access to the latest information. Implement data validation, cleansing, and enrichment steps to ensure data is accurate and reliable. Monitor pipeline performance and set up alerts for failures or anomalies. Document data lineage and transformation logic to support governance and troubleshooting.
Did you know? Qrvey connects to any data source, structured or unstructured. Connections tell Qrvey where to fetch data from.
Step 4: Implement Metadata Management and Governance
As your data lake grows, effective metadata management and governance become increasingly important. Deploy a data catalog (such as AWS Glue Data Catalog or Apache Atlas) to organize datasets, document schema, and track data lineage. Define governance policies for data access, retention, and compliance with regulatory requirements (such as GDPR or HIPAA).
Implement role-based access controls to restrict sensitive data to authorized users, and set up auditing and monitoring to track data usage and detect potential security incidents. Regularly review and update governance policies to reflect changing business needs and regulatory landscapes. Provide training and documentation to ensure all users understand their responsibilities and the importance of data governance.
Step 5: Enable Analytics, Security, and Self-Service
The true value of a data lake is realized when users can easily access, analyze, and derive insights from data. Integrate analytics platforms (such as Qrvey, Databricks, or Power BI) to enable data exploration, visualization, and advanced analytics. Set up robust security controls, including encryption at rest and in transit, identity and access management (IAM), and continuous monitoring for threats.
Empower users with self-service tools that allow them to discover, query, and analyze data without relying on IT. Provide training and support to drive adoption and maximize the impact of your data lake. Continuously evaluate and enhance your analytics and security capabilities to stay ahead of evolving threats and business requirements.
How Does a Data Lake Fit into a Modern Data Platform?
A data lake is not just a standalone repository—it’s the foundation of a modern, agile data platform that supports a wide range of analytics and operational use cases. Here’s how it fits into the bigger picture:
- Centralized Data Hub: The data lake acts as the single source of truth for all organizational data, consolidating information from disparate systems and breaking down silos. This centralization enables consistent, organization-wide analytics and reporting.
- Integration Layer: Modern data platforms integrate the data lake with data warehouses, data marts, and operational systems, enabling seamless data flow across the enterprise. This allows organizations to leverage the strengths of each platform—using the data lake for raw, unstructured data and the warehouse for structured, high-performance analytics.
- Self-Service Analytics: By democratizing access to data, data lakes empower business users, analysts, and data scientists to explore and analyze data without IT bottlenecks. Self-service tools and embedded analytics platforms (like Qrvey) make it easy for users to create dashboards, run queries, and generate insights on demand.
- Scalable and Flexible Architecture: Data lakes are designed to scale with your organization’s needs, supporting new data sources, analytics tools, and business requirements as they arise. This flexibility ensures your data platform remains agile and responsive to change.
- Advanced Analytics and AI: With access to raw, granular data, organizations can build and deploy machine learning models, perform predictive analytics, and support real-time decision-making. The data lake serves as the foundation for innovation and competitive advantage.
Platform Example: Qrvey’s embedded analytics operations enable organizations to deliver personalized dashboards, operational insights, and multi-tenant analytics at scale, all while maintaining robust security and governance.
Six Data Lake Best Practices to Follow
1. Establish Clear Governance
Effective governance is the backbone of a successful data lake. Start by defining clear roles and responsibilities for data stewardship, ownership, and access. Develop comprehensive policies that cover data quality, privacy, retention, and compliance with regulations such as GDPR or HIPAA. Implement a governance framework that includes regular audits, data lineage tracking, and standardized processes for onboarding new data sources. Encourage cross-functional collaboration between IT, security, and business teams to ensure policies are practical and enforced.
By prioritizing governance from the outset, you prevent your data lake from devolving into a “data swamp” and ensure that data remains trustworthy, secure, and valuable for all users.
2. Automate Data Ingestion and Processing
Manual data ingestion is error-prone and unsustainable at scale. Invest in robust ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) pipelines using tools like Apache NiFi, AWS Glue, or Azure Data Factory. Automate the extraction of data from diverse sources, apply validation and cleansing rules, and load it into the data lake in near real-time.
Automation not only improves data quality and consistency but also accelerates time-to-insight. Monitor pipeline performance with dashboards and alerts, and design workflows to gracefully handle failures or schema changes. This approach ensures your data lake remains up-to-date, reliable, and ready for advanced analytics.
3. Implement Robust Security and Access Controls
Security must be embedded at every layer of your data lake architecture. Encrypt data both at rest and in transit using industry-standard protocols. Use identity and access management (IAM) to enforce role-based access, ensuring that only authorized users can view or modify sensitive datasets. Regularly audit access logs and monitor for unusual activity to detect potential threats early.
Integrate with your organization’s single sign-on (SSO) and multi-factor authentication (MFA) systems for enhanced protection. Stay current with security patches and compliance requirements, and conduct periodic penetration testing. By making security a continuous priority, you protect your organization’s most valuable asset—its data.
4. Promote Data Cataloging, Discovery, and Lineage
As your data lake grows, so does the challenge of finding and understanding available data. Deploy a modern data catalog (such as AWS Glue Data Catalog, Apache Atlas, or Alation) to document datasets, schemas, and metadata. Enable intuitive search and discovery features so users can quickly locate relevant data for their projects.
Track data lineage to provide transparency into how data is sourced, transformed, and used across the organization. Encourage teams to annotate datasets with business context, quality scores, and usage examples. A well-maintained catalog not only boosts productivity but also supports compliance and fosters a culture of data literacy.
5. Enable Self-Service Analytics and Multi-Tenant Data Consumption
Empower users across the organization to explore and analyze data without relying on IT bottlenecks. Provide intuitive, self-service analytics tools that support ad hoc queries, dashboard creation, and data visualization. For SaaS providers or organizations with multiple business units, implement multi-tenant architectures that ensure data isolation, security, and governance for each tenant.
Platforms like Qrvey excel in this area, offering embedded analytics, fine-grained access controls, and seamless integration with cloud-native data lakes. By enabling self-service and multi-tenant capabilities, you maximize the value of your data lake and drive widespread adoption.
6. Monitor, Optimize, and Continuously Improve
A data lake is not a “set it and forget it” solution. Continuously monitor storage usage, query performance, and pipeline health with automated dashboards and alerts. Analyze usage patterns to identify popular datasets, unused assets, or potential bottlenecks. Optimize storage costs by tiering data—moving infrequently accessed data to lower-cost storage classes.
Solicit feedback from users to identify pain points and opportunities for improvement. Regularly review and update best practices, governance policies, and technology choices to stay ahead of evolving business needs and regulatory requirements. Continuous improvement ensures your data lake remains a strategic asset, not a liability.

Common Challenges and How to Avoid Them
Challenge 1: Data Swamps (Lack of Governance and Organization)
A data lake’s greatest strength—its ability to store any data in any format—can quickly become its biggest weakness if not managed properly. Without strong governance, clear metadata, and regular maintenance, a data lake can devolve into a “data swamp,” where data is disorganized, poorly documented, and difficult to find or trust.
This leads to wasted time, unreliable analytics, and frustrated users. To avoid this, implement robust metadata management and cataloging from day one. Use automated tools to tag, index, and track data lineage. Schedule regular audits to clean up obsolete or redundant datasets. Foster a culture of data stewardship, where every team is responsible for the quality and documentation of their data contributions.
Challenge 2: Security Risks and Data Privacy
Storing large volumes of sensitive data in a centralized repository makes data lakes an attractive target for cyberattacks and internal misuse. Common security risks include unauthorized access, data leaks, and non-compliance with regulations like GDPR or HIPAA. Many organizations underestimate the complexity of securing a data lake, especially when multiple users and applications require access.
To mitigate these risks, enforce encryption at rest and in transit, implement strict identity and access management (IAM), and regularly audit access logs. Integrate with your organization’s SSO and MFA systems, and stay current with security patches. Establish clear policies for data classification, retention, and deletion to ensure compliance and minimize exposure.
Challenge 3: Performance Bottlenecks and Query Latency
As data lakes grow, performance issues can emerge—especially when running complex queries on massive datasets. Poorly designed storage layouts, lack of partitioning, or insufficient compute resources can lead to slow query response times and frustrated users. To address this, design your data lake with scalability in mind.
Partition large datasets by date, region, or other relevant keys to speed up queries. Use columnar storage formats like Parquet or ORC for efficient analytics. Leverage distributed processing engines (e.g., Apache Spark, Databricks) and scale compute resources dynamically based on workload. Monitor query performance and optimize pipelines regularly to maintain a responsive analytics environment.
Challenge 4: Cost Overruns and Uncontrolled Growth
The pay-as-you-go model of cloud storage is a double-edged sword: while it offers flexibility, it can also lead to unexpected costs if data growth is not monitored and managed. Storing unnecessary or duplicate data, retaining obsolete datasets, or failing to tier storage can quickly inflate your cloud bill.
To control costs of your data lake, implement data lifecycle management policies that automatically move infrequently accessed data to lower-cost storage classes or delete it after a set period. Use monitoring tools to track storage usage and set alerts for unusual spikes. Regularly review and clean up unused datasets, and educate teams on the financial impact of their data practices.
Challenge 5: Low User Adoption and Complexity
A data lake is only valuable if people use it. Complex tools, poor documentation, or lack of training can hinder adoption and limit the return on your investment. Users may revert to old habits or create shadow IT solutions if the data lake feels inaccessible or confusing.
To drive adoption, invest in intuitive, self-service analytics platforms that lower the barrier to entry. Provide comprehensive onboarding, training, and ongoing support. Encourage a culture of data literacy by sharing success stories and demonstrating the business impact of data-driven decisions. Solicit feedback from users and continuously improve the user experience.
Three Examples of Cloud Data Lake Architectures
Example 1: AWS Data Lake for Enterprise Analytics
A leading retail enterprise built its data lake on Amazon Web Services (AWS) to centralize data from point-of-sale systems, e-commerce platforms, and IoT devices in stores. Using Amazon S3 as the storage backbone, the company ingests terabytes of structured and unstructured data daily via AWS Glue and Kinesis Data Streams. Metadata is managed with AWS Glue Data Catalog, enabling easy discovery and governance.
Data scientists use Amazon Athena for serverless SQL queries and SageMaker for machine learning, while business analysts access dashboards through Amazon QuickSight. The architecture supports both batch and real-time analytics, scales elastically with demand, and leverages AWS’s robust security features, including encryption and IAM. This setup has reduced time-to-insight from days to hours and enabled advanced use cases like personalized marketing and inventory optimization.
Example 2: Azure Data Lake for Healthcare Compliance
A healthcare provider adopted Microsoft Azure Data Lake to securely store and analyze patient records, medical images, and IoT device data from hospital equipment. Data is ingested using Azure Data Factory, which orchestrates ETL pipelines from electronic health record (EHR) systems, lab results, and wearable devices. Raw data lands in Azure Data Lake Storage Gen2, where it is cataloged and governed using Azure Purview.
Data engineers use Azure Databricks for large-scale processing and transformation, while compliance teams leverage built-in auditing and access controls to ensure HIPAA and GDPR compliance. Power BI dashboards provide clinicians and administrators with real-time insights into patient outcomes and operational efficiency. The architecture’s scalability and security have enabled the provider to innovate with predictive analytics and remote patient monitoring, all while maintaining strict regulatory standards.
Example 3: Qrvey-Powered SaaS Data Lake for Multi-Tenant Analytics
A SaaS company serving the financial sector needed a data lake that could support multi-tenant analytics for hundreds of clients, each with strict data isolation and governance requirements. They chose a Qrvey-powered architecture, combining cloud object storage (such as AWS S3 or Azure Data Lake Storage) with Qrvey’s embedded analytics platform. Data from client applications is ingested via automated ETL pipelines, tagged with tenant metadata, and cataloged for discovery.
Qrvey’s platform provides fine-grained access controls, ensuring each client can only access their own data and analytics. Business users create custom dashboards and reports through a self-service interface, while administrators monitor usage and compliance from a centralized console. The architecture supports rapid onboarding of new clients, seamless scaling, and robust security, making it ideal for SaaS providers who need to deliver analytics as a service without compromising on governance or user experience.
See How Qrvey Helps You Succeed with its built-in Data Lake
Building a scalable, secure, and high-value data lake is no longer a luxury—it’s a necessity for organizations that want to stay competitive and data-driven. By following the proven steps and best practices outlined in this guide, you can avoid common pitfalls, empower your teams, and unlock new opportunities for innovation and growth. But the journey doesn’t end with architecture and ingestion; true success comes from making your data accessible, actionable, and governed for every user and customer.
Qrvey’s multi-tenant analytics platform is purpose-built to help SaaS companies get the most out of their data lakes. With embedded analytics, robust governance, and seamless integration with cloud-native storage, Qrvey enables you to deliver secure, scalable insights to every user—without the complexity or overhead of traditional BI tools. Whether you’re just starting your data lake journey or looking to modernize your analytics stack, Qrvey provides the tools and expertise to accelerate your success.


David is the Chief Technology Officer at Qrvey, the leading provider of embedded analytics software for B2B SaaS companies. With extensive experience in software development and a passion for innovation, David plays a pivotal role in helping companies successfully transition from traditional reporting features to highly customizable analytics experiences that delight SaaS end-users.
Drawing from his deep technical expertise and industry insights, David leads Qrvey’s engineering team in developing cutting-edge analytics solutions that empower product teams to seamlessly integrate robust data visualizations and interactive dashboards into their applications. His commitment to staying ahead of the curve ensures that Qrvey’s platform continuously evolves to meet the ever-changing needs of the SaaS industry.
David shares his wealth of knowledge and best practices on topics related to embedded analytics, data visualization, and the technical considerations involved in building data-driven SaaS products.
Popular Posts

Why is Multi-Tenant Analytics So Hard?
BLOG
Creating performant, secure, and scalable multi-tenant analytics requires overcoming steep engineering challenges that stretch the limits of...

How We Define Embedded Analytics
BLOG
Embedded analytics comes in many forms, but at Qrvey we focus exclusively on embedded analytics for SaaS applications. Discover the differences here...

White Labeling Your Analytics for Success
BLOG
When using third party analytics software you want it to blend in seamlessly to your application. Learn more on how and why this is important for user experience.