Embedded Analytics Platform
Build Less Software
Development teams build less in-house with all the user-facing components of an enterprise scale, embedded analytics solution.
Get a Demo Watch a Demo
Embedded Analytics Solutions Can be a Powerful Differentiator
Increase Customer Satisfaction
Grow
Revenue
Lower Developer
Effort
Reduce Feature
Requests
Embedded Analytics Gives You the Freedom to Design Unique User Experiences
Qrvey’s comprehensive embedded analytics software features enables you to design more customizable analytics experiences for your end users.

Easy-to-Build Charts
Qrvey’s easy-to-use, self-service chart builder is fully interactive

Create Templates
for Easy On-Boarding
Give your users templates as a starting point for building their own dashboards and reports

Workflow
Embed our automation workflow builder to connect data via alerts and actions
Embedded Analytics Software for Developers
Maximize Developer Efficiency
Engineering teams can deliver robust analytics in a fraction of the time. Qrvey is 100% embeddable and ready for integration into your SaaS application.
JavaScript Widgets (no iframes anywhere)
Robust API for Custom Interface Design
Webhooks to Push Data On Any Schedule
Multi-Tenant Security with a Native Semantic Layer
Granular Data Sync Schedules

Embedded Analytics Software
Building Yourself Takes Too Long
Keep your focus on your core capabilities. Our focus is embedded analytics for multi-tenant analytics within SaaS applications. Take advantage of our focus and build less software.
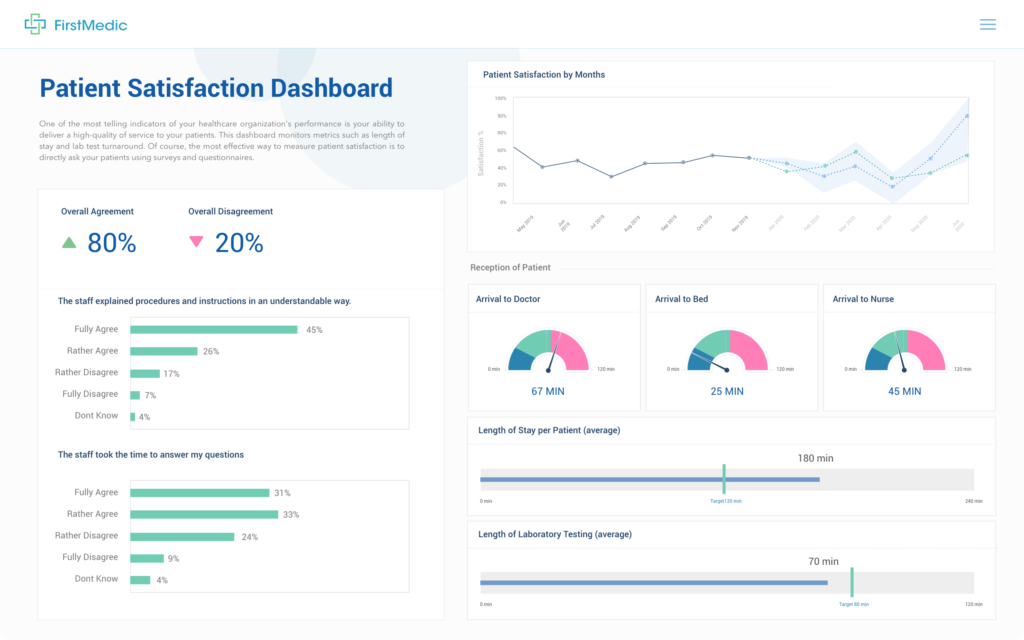
DATA MANAGEMENT FOR EMBEDDED ANALYTICS
Multi-Tenant Data Lake Optimized for Embedded Analytics
Engineering teams get bogged down creating an analytics layer for multi-tenant analytics. Qrvey gives you the data engine specifically to embedded analytics to get you moving faster.
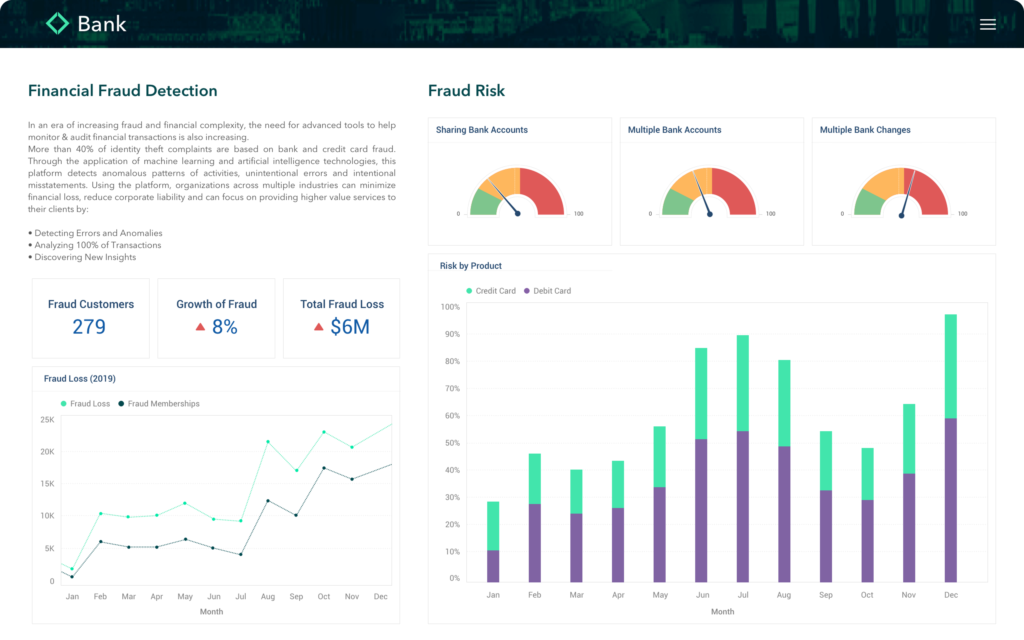
Embedded Cloud Native Analytics
Secure & Scalable For Peace of Mind
Qrvey is a deployed solution to your cloud environment. Qrvey’s solution scales to the largest SaaS platforms while keeping your data in place and secure.


CASE STUDY
See How JobNimbus deployed Qrvey to 6,000 customers and saw an immediate reduction in customer churn.
See what our partners have to say.

Herman Haynes
CIO @ Global K9 Protection Group
Adding Qrvey to our business was like turning on a light switch.

Ryan Quackenbush
Senior PM @ JobNimbus
We can’t speak highly enough of the stellar team at Qrvey. Within months of deploying Qrvey, JobNimbus achieved 70% adoption among large
enterprise users.

Dadou Jahanbani
CTO @ Impexium
Qrvey allowed Impexium to go to market quickly and get analytics into the hands of our customers.

Srinivasa Sridharan
CTO @ Setvi
Excellent product and customer support.
asasasasasasas sasasasas





More Insights

Why is Multi-Tenant Analytics So Hard?
BLOG
Creating performant, secure, and scalable multi-tenant analytics requires overcoming steep engineering challenges that stretch the limits of...

Pricing Strategies to Maximize Revenue from Analytics
GUIDE
Unlock the full potential of your SaaS business with our comprehensive guide on pricing and packaging strategies.

How JobNimbus deployed Qrvey to 6,000 customers
CASE STUDY
Discover how JobNimbus deployed Qrvey to 6,000 customers and saw an immediate reduction in customer churn....
See Qrvey in Action
Learn about Qrvey’s embedded analytics platform and get quick answers to your questions by booking a guided product tour with our experts.